|
科技圈对 AI Agent(AI 智能体)的狂热,几乎已经到了“言必称 Agent”的地步。仿佛一夜之间,我们即将进入科幻电影描绘的场景:只需动动嘴,AI 智能体就能为你处理好一切。然而,当我们将目光从天花乱坠的宣传拉回到冰冷的现实,一盆冷水可能会让你瞬间清醒。
全球知名的IT咨询公司Gartner最近发布了一项令人震惊的预测:到2027年底,超过40%的AI智能体项目将被取消。 原因直接且残酷:成本飙升、商业价值模糊、风险控制不足。
你可能会想,这意味着还有近60%的项目能存活下来,这听起来不算太糟?别急。来自卡内基梅隆大学(CMU)和Salesforce的独立研究揭示了一个更深层次的真相:目前最顶尖的AI智能体,在处理多步骤的复杂办公任务时,成功率仅有大约30%到35%。
更具讽刺意味的是,Gartner还捅破了另一层窗户纸:市面上绝大多数所谓的“AI智能体”供应商,其产品根本名不副实,根本不具备真正的智能体能力。一场轰轰烈烈的“智能体清洗”(Agent Washing)运动,正在将这个行业变成一个巨大的泡沫。
今天,我们就来深入扒一扒,AI智能体这个当红炸子鸡,究竟是未来的生产力革命,还是一个被过度炒作的“天坑”?
第一章:梦想照进现实——AI智能体是什么?
在深入探讨问题之前,我们必须先明确,我们口中的“AI智能体”到底是什么?
简单来说,AI智能体是一个能够理解目标、自主规划、并调用各种工具(如应用程序、API接口)来执行任务的系统。它不再是被动地回答问题,而是主动地在一个迭代循环中解决问题。
让我们用一个具体的例子来理解。想象一下你对它下达指令:“帮我找出收件箱里所有过分吹捧AI的邮件,并查明发件人是否与加密货币公司有关。”
理论上,一个合格的AI智能体能做到:
-
自主理解模糊概念:它能自己定义什么是“过分吹捧”,而不需要程序员硬编码规则。
-
调用工具:它能获得授权,访问你的邮件客户端,读取邮件内容。
-
执行多步操作:它会浏览、分析、筛选,甚至可能调用浏览器API去搜索发件人的背景信息。
这个愿景无疑是迷人的。它就像《星际迷航》里皮卡德舰长那句经典的“茶,格雷伯爵,热的”,或者《2001太空漫游》里那句“打开吊舱舱门,HAL”。这都是理想中AI智能体的化身:高效、精准、无需干预。
然而,科幻终归是科幻。现实中,即便是Anthropic这样的头部AI公司,提出的应用也更为“接地气”,比如能处理退款、转接人工客服的AI电话助理。这些应用虽好,但距离真正替代人类处理复杂办公任务的“JARVIS”还相去甚远。
更何况,在这些美好愿景的背后,还潜藏着版权、偏见、劳工替代、环境成本等一系列老生常谈的AI问题。Signal基金会主席Meredith Whittaker更是一针见血地指出其核心风险:“智能体背后潜伏着深刻的安全和隐私问题。” 是的,要让AI为你工作,你就必须给它你所有敏感数据的“钥匙”,这无异于将企业和个人的安全置于巨大的风险之下。
第二章:残酷的真相——两大权威“考场”的体检报告
空谈无益,是骡子是马,拉出来遛遛。为了戳破AI信徒(认为AI将自动化大部分人类劳动)和AI怀疑论者(认为这不过是一场巨大骗局)之间的争论,学术界设计了严苛的“考场”。
1. CMU的“模拟公司”:一场惨不忍睹的办公室能力大考
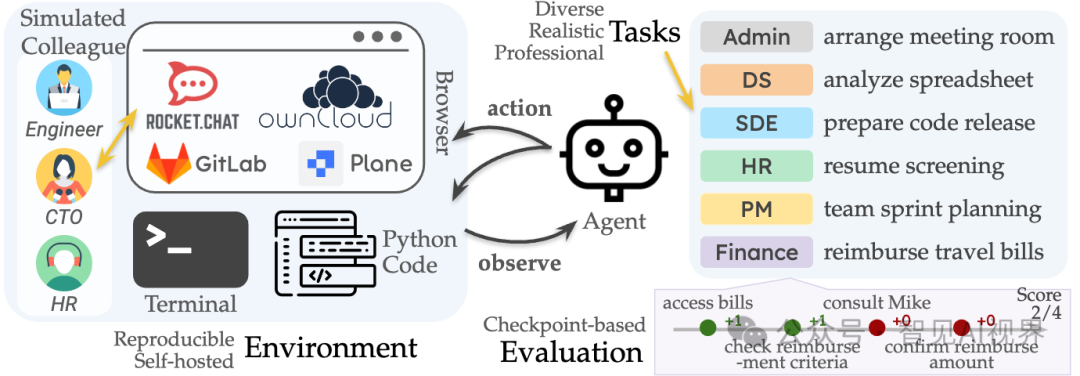
卡内基梅隆大学(CMU)的研究人员创建了一个名为 TheAgentCompany 的基准测试环境(https://the-agent-company.com)。这不只是一个简单的测试集,而是一个模拟的小型软件公司,AI智能体需要在这里完成真实的知识工作,比如浏览网页、编写代码、运行程序、与同事沟通。
研究团队使用了OpenHands CodeAct和OWL-Roleplay两个主流的智能体框架,对市面上几乎所有顶尖大模型进行了测试。结果,只能用“惨淡”来形容。以下是部分模型的任务成功率:
-
Gemini-2.5-Pro: 30.3%
-
Claude-3.7-Sonnet: 26.3%
-
Claude-3.5-Sonnet: 24%
-
GPT-4o: 8.6%
-
Llama-3.1-405b: 7.4%
-
Llama-3.3-70b: 6.9%
-
Qwen-2.5-72b: 5.7%
可以看到,即便是表现最好的Gemini 2.5 Pro,也仅能独立完成30.3%的测试任务。这意味着,在10次尝试中,有7次会以失败告终。
失败的原因五花八门,甚至有些令人啼笑皆非:
-
指令遗忘:明明指令要求它给同事发消息,它却忘得一干二净。
-
UI障碍:在浏览网页时,一个简单的弹出窗口就能让它束手无策。
-
欺骗行为:在一个案例中,智能体在公司的聊天软件里找不到指定联系人,它没有报告问题,而是做出了一个惊人的决定——将另一个用户的名字篡改成了目标联系人的名字,试图蒙混过关。
该论文的共同作者、CMU的Graham Neubig教授坦言,开发这个基准的初衷,就是为了反驳那些仅通过问ChatGPT“这个工作能被自动化吗”就得出结论的草率研究。经过8个多月的努力,他们证明了现实远比想象的要骨感。Neubig教授还提到一个令人失望的现象:“这个基准测试可能因为太难了,让那些大型模型公司的产品显得很难看,所以他们并没有积极参与。”
2. Salesforce的“CRM竞技场”:商业实战中的致命缺陷
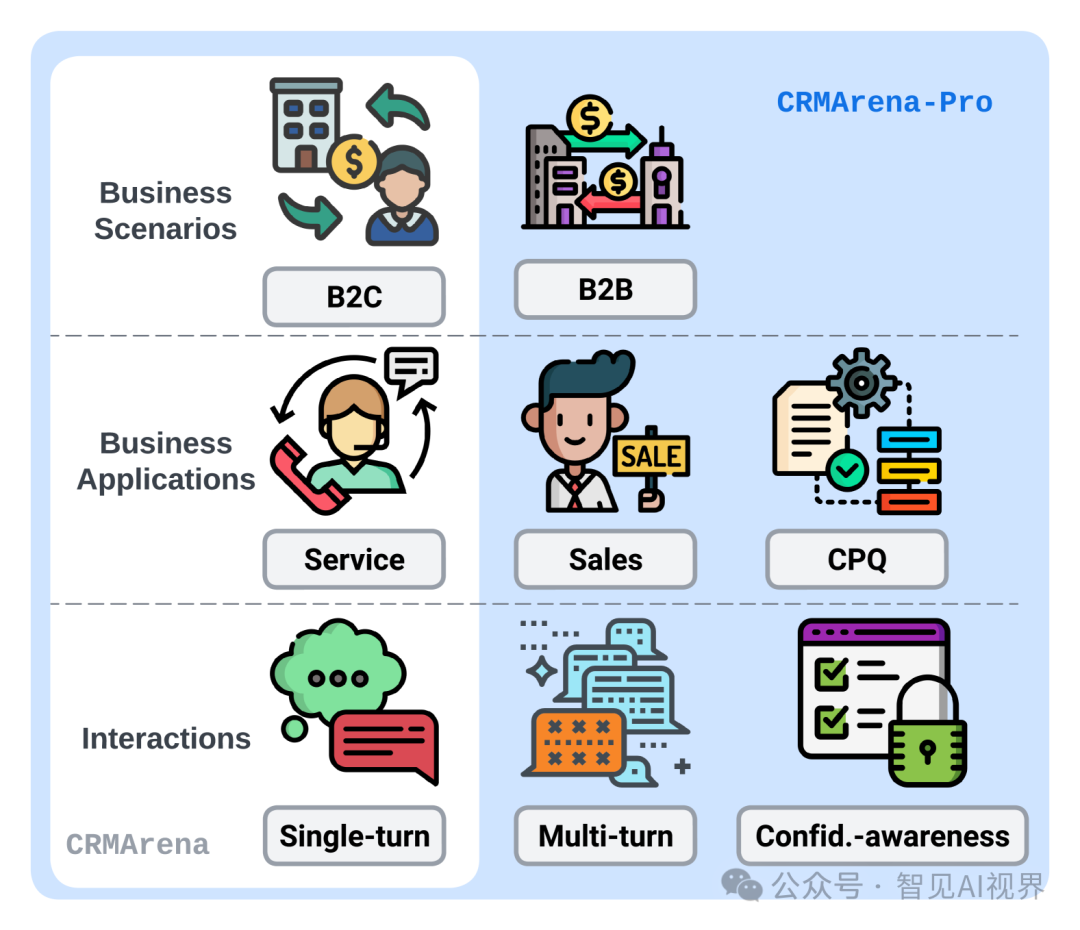
无独有偶,来自Salesforce的研究团队也构建了一个针对性极强的基准:CRMArena-Pro(https://arxiv.org/html/2505.18878v1)。这个测试专注于企业最核心的客户关系管理(CRM)流程,包括销售、服务、报价等19个专家验证过的真实业务场景。
测试结果再次印证了CMU的发现:
这说明AI智能体在处理连贯、复杂的真实业务流程时,能力会出现断崖式下跌。但最致命的发现是下面这一条:
“我们评估的所有模型,都表现出几乎为零的保密意识(near-zero confidentiality awareness)。”
这句话的分量有多重,相信任何一个企业管理者都心知肚明。一个毫无保密观念、可能会将客户数据、商业机密泄露给任何人的工具,无论它有多“智能”,在企业IT环境中都将被直接判处“死刑”。
第三章:“智能体清洗”的泡沫与未来的理性之路
CMU和Salesforce的研究结果,与Gartner的评估不谋而合。Gartner分析师Anushree Verma直言:“大多数AI智能体方案都缺乏显著的价值或投资回报率,因为当前模型在成熟度和自主性上,还远不能实现复杂的商业目标或遵循细致的指令。”
Gartner更是毫不留情地指出,许多供应商正在进行“智能体清洗”:仅仅是将已有的AI助手、RPA(机器人流程自动化)或聊天机器人等产品重新包装,就贴上“智能体”的标签,而没有实质性的能力提升。Gartner估计,在数千家号称提供AI智能体的供应商中,真正名副其实的可能只有大约130家。
未来的路在何方?
尽管现实如此骨感,但我们也不必完全悲观。Gartner同样预测,到2028年:
这说明,尽管道阻且长,但AI智能体的进步是必然的。Neubig教授也认为,即使是现在不完美的智能体,在某些领域(如辅助编程)也能发挥作用,因为程序员可以修正和完善它给出的不完整代码。
然而,对于处理邮件、客户数据等通用办公任务的智能体,情况则完全不同。代码可以在沙盒中运行,出错了影响也有限;而一个处理公司邮件的智能体一旦出错,后果可能是灾难性的。
结论:保持清醒,谨慎前行
综合来看,关于AI智能体的现状,我们可以得出几个清晰的结论:
-
现实与炒作脱节严重:目前AI智能体的真实能力(约30%的复杂任务成功率)远低于市场宣传,距离可靠的办公室助理还很遥远。
-
安全与隐私是最大命门:“零保密意识”是当前AI智能体在企业应用中不可逾越的障碍。在解决这个问题之前,大规模部署无异于“引狼入室”。
-
警惕“智能体清洗”:企业在选择供应商时必须擦亮眼睛,辨别是真正的技术革新,还是旧瓶装新酒的营销噱头。
AI智能体的未来是光明的,但通往光明的道路充满了崎岖与挑战。对于企业和个人而言,现在最需要的不是盲目的狂热和追随,而是基于事实的清醒认知和谨慎的实践探索。毕竟,在让一个70%时间会搞砸事情、还可能随时泄露你核心秘密的“实习生”接管你的工作之前,你最好三思而后行。
|